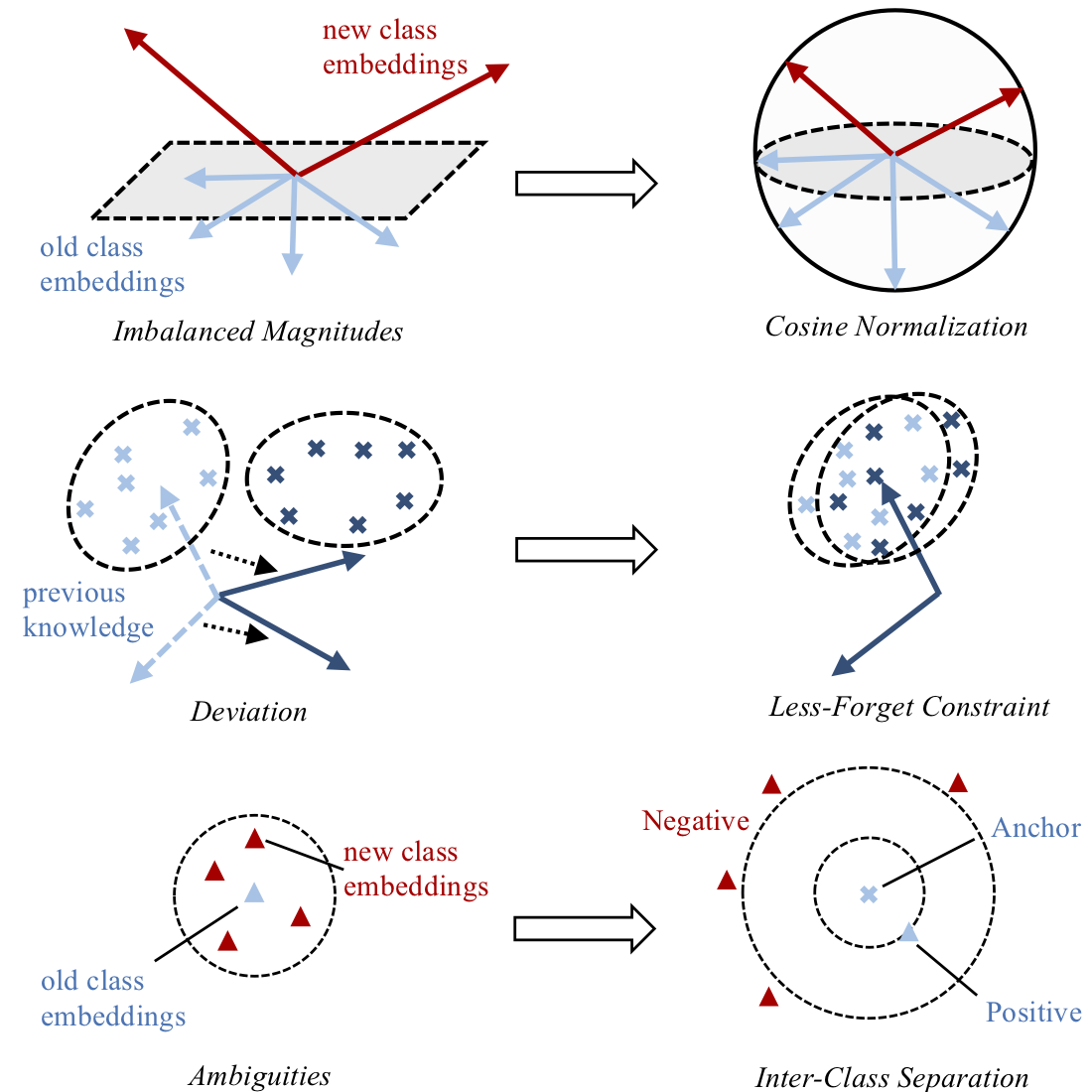
Fig 1. Illustration of the adverse effects caused by the imbalance between old and new classes in multi-class incremental learning, and how our approach tackle them.
Abstract
Conventionally, deep neural networks are trained offline, relying on a large dataset prepared in advance. This paradigm is often challenged in real-world applications, e.g. online services that involve continuous streams of incoming data. Recently, incremental learning receives increasing attention, and is considered as a promising solution to the practical challenges mentioned above. However, it has been observed that incremental learning is subject to a fundamental difficulty – catastrophic forgetting, namely adapting a model to new data often results in severe performance degradation on previous tasks or classes. Our study reveals that the imbalance between previous and new data is a crucial cause to this problem. In this work, we develop a new framework for incrementally learning a unified classifier, i.e. a classifier that treats both old and new classes uniformly. Specifically, we incorporate three components, cosine normalization, less-forget constraint, and inter-class separation, to mitigate the adverse effects of the imbalance. Experiments show that the proposed method can effectively rebalance the training process, thus obtaining superior performance compared to the existing methods. On CIFAR-100 and ImageNet, our method can reduce the classification errors by more than 6% and 13% respectively, under the incremental setting of 10 phases.Architcture
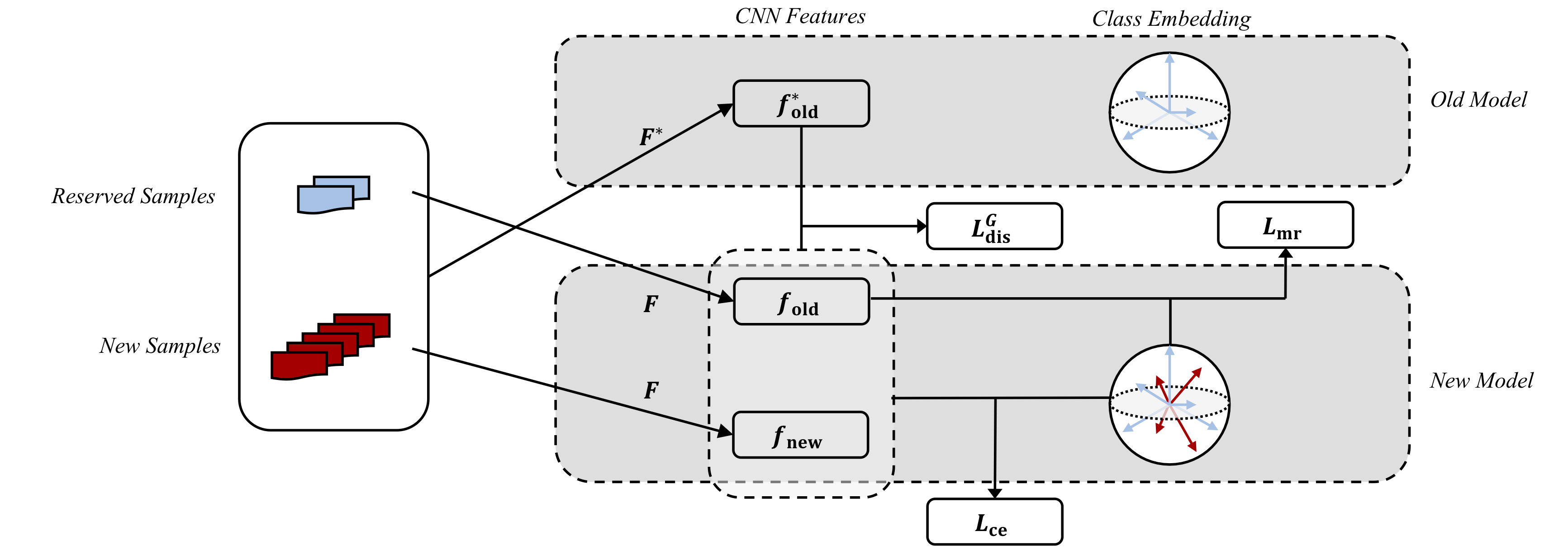
Fig 2. Illustration of our approach for multi-class incremental learning. Due to cosine normalization, the features and class embeddings lie in a high-dimensional sphere geometrically. There are three types of loss involved in the incremental process. Besides the cross-entropy loss \(L_{\mathrm{ce}}\) computed on all classes, \(L^{\mathrm{G}}_{\mathrm{dis}}\) is a novel distillation loss computed on the features (less-forget constraint), and \(L_{\mathrm{mr}}\) is a variant of margin ranking loss to separate the old and new classes (inter-class separation).
Performance
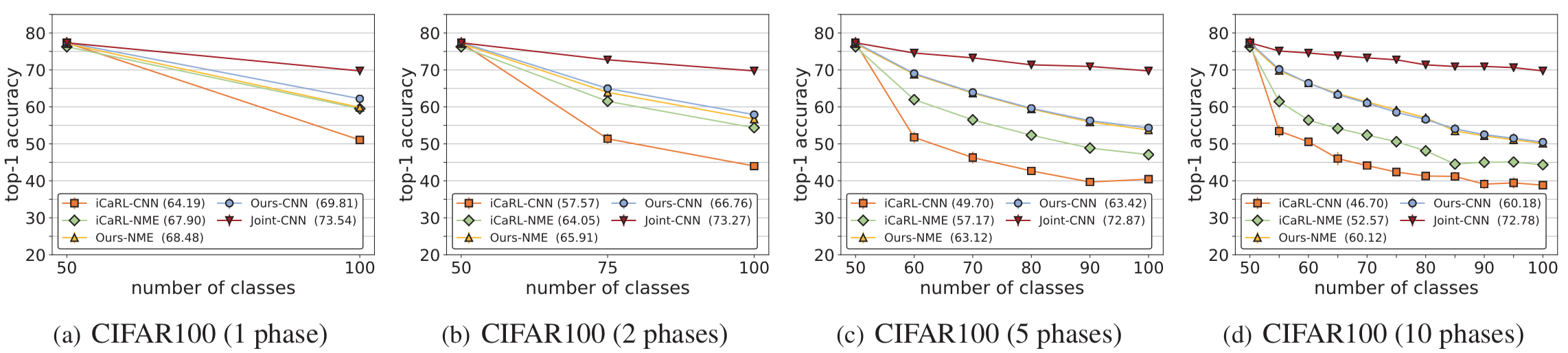
Fig 3. The performance on CIFAR100. The average and standard deviations are obtained over three runs.
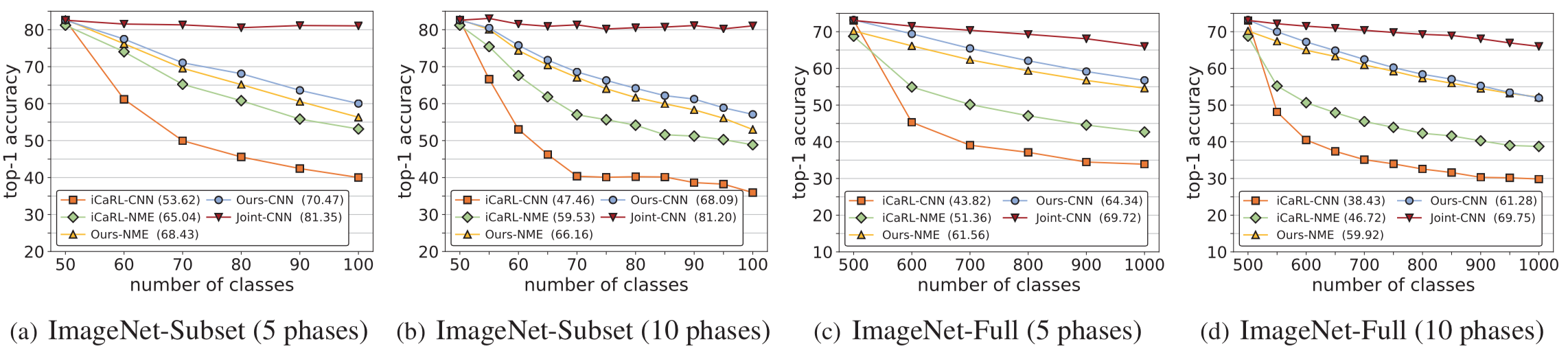
Fig 4. The performance on ImageNet. Reported on ImageNet-Subset (100 classes) and ImageNet-Full (1000 classes).